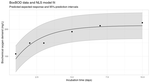
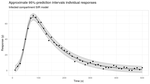
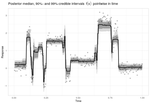
Blogging mostly about Statistics and R
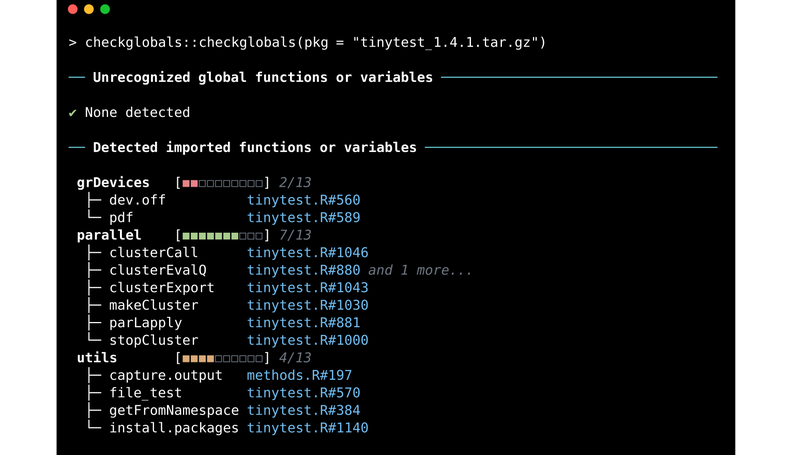
Introduction An important aspect of writing an R-script or an R-package is ensuring reproducibility and maintainability of the developed code, not only for others, but also for our future selves.